
IA Ética, IA Responsável e Explicabilidade de IA
A inteligência artificial (IA) tem se tornado cada vez mais presente em nossas vidas, mas com ela surgem questões importantes sobre IA ética, explicável e […]
A inteligência artificial (IA) tem se tornado cada vez mais presente em nossas vidas, mas com ela surgem questões importantes sobre IA ética, explicável e […]

Fiz mais um review de livro da Editora Packt, desta vez foi do Azure Data Factory Cookbook – 2nd edition. Um guia essencial para profissionais […]
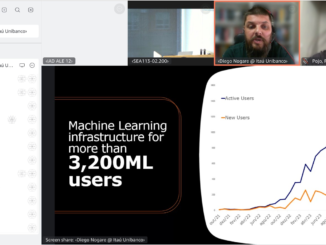
O Itaú Unibanco, maior instituição financeira da América Latina, está revolucionando seus serviços bancários por meio da transformação digital. Em parceria com a Amazon Web […]

Seja bem-vindo ao meu repositório de Machine Learning no GitHub! Aqui, você encontrará os códigos que desenvolvi durante a disciplina de Aprendizagem de Máquina do […]

Review do livro “50 Algorithms Every Programmer Should Know – 2nd edition“, que foi escrito por Imran Ahmad e publicado pela Packt Pub. Neste livro […]

A era digital trouxe consigo uma nova figura: o Citizen Data Scientist. Esse é um termo que vem ganhando cada vez mais destaque no mundo […]

Tive a inspiração para esse texto há algumas semanas, durante o carnaval, quando me convidaram para ir à um bloquinho. Não sou muito fã desta […]
Copyright © 2024 | WordPress Theme by MH Themes
