Fala galera, como prometido algumas semanas atrás vou escrever uma série de posts falando sobre os algoritmos de Data Mining existentes no SQL Server 2014. Hoje vamos cobrir o uso do algoritmo de Árvore de Decisão, que implementa o algoritmo Microsft Decision Tree.
Como já foi falado no primeiro post, este algoritmo de classificação é responsável por criar uma representação visual que chamamos de árvore por contem um nó raíz, nós intermediários que são as ramificações e os últimos nós representados que são as folhas.
É importante conhecer os dados que serão trabalhados para poder definir o que são atributos de entrada e o que são atributos preditivos. Basicamente, os atributos de entradas são colunas do banco de dados que podem influenciar o resultado final, e o resultado final é a coluna preditiva. Imagine um cenário onde o objetivo é classificar pessoas que são possíveis compradores do livro Do Banco de Dados Relacional à Tomada de Decisão. Então neste caso a coluna preditiva do banco é se o cara comprou ou não o livro. As colunas de input são as colunas que tem alguma influência sobre a compra do livro, por exemplo, o idioma, a área de atuação, interesse técnico, etc. O algoritmo, com base nestas informações de input e predição, estrutura os nós da árvore classificando o que é relevante nas ramificações e entregando um (ou mais) caminhos ideais para chegar até as folhas. Pensando por esse lado, foi constatado que das 10 vendas que o livro teve, 8 falam idioma Português, 7 trabalham na área de Banco de Dados e somente 3 tem interesse técnico. Quando estes dados são processados pelo algoritmo e apresentado através da Árvore de Decisão, é possível ver claramente qual é o melhor caminho para segmentar o público que compraria o livro. São profissionais que falam Português e que trabalham na área de Banco de Dados, mas o interesse técnico não importa. Se fizer uma campanha de marketing direcionada para este público, a chance de vender o livro é muito maior do que enviar para um grupo de pessoas que falam Inglês e trabalham na área de Nutrição.
Bom, depois desse exemplo para entender o funcionamento do algoritmo, vamos começar um exemplo utilizando o Adventure Works.
Primeira coisa é necessário criar um novo projeto do tipo SSAS com Data Mining. Vou levar em conta que você sabe criar um Data Source apontando para o AdventureWorksDW2012 e um Data Source View apontando para a vTargetMail.
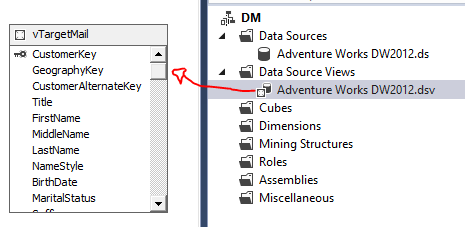
O próximo passo é onde começa a mineração de dados, procure na Solution Explorer o item de Mining Structure e clique com o botão direito do mouse, em seguida, aponte para New Mining Structure.
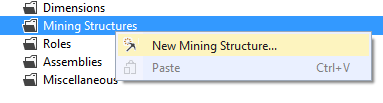
Neste momento uma tela de abre e permite que você informe onde estão os dados de origem. Como utilizaremos o Data Warehouse para consumir os dados, deixe marcada a opção que é apresentada.
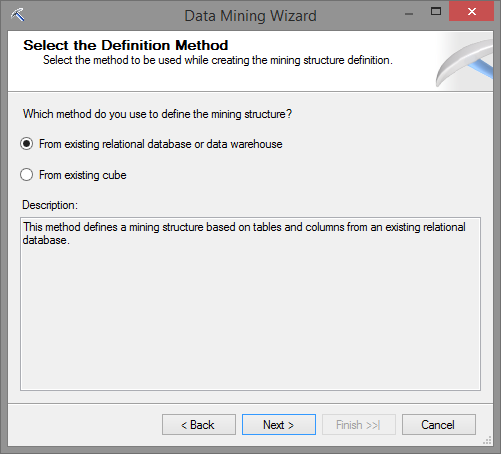
Ao avançar para a próxima tela, você deve escolher qual algoritmo vai utilizar para sua mineração. No caso deste exemplo, mantenha escolhido o default, que é Decision Tree.
Na tela seguinte, você informa qual é o Data Source View que possui a conexão com sua base de dados de origem. Como foi criado somente um Data Source View, somente ele é apresentado.
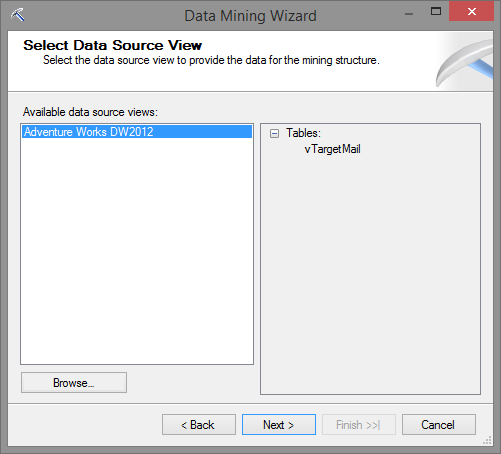
Ao avançar, o wizard pergunta quais tabelas são Case e quais são Nested. Mantenha a tabela (eu sei que é uma view!!!!) vTargetMail marcada como Case e avance.
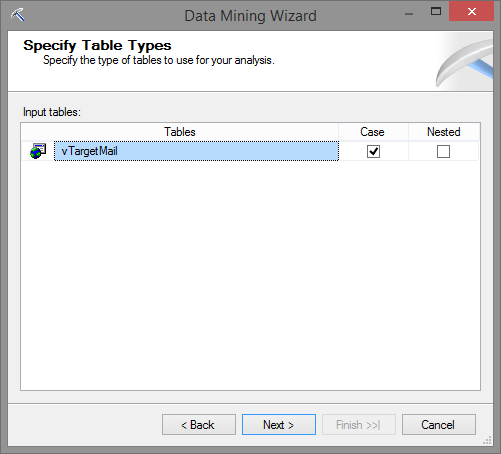
Neste momento é hora de selecionar quais colunas são de entrada e quais são preditivas. Ao bater o olho na tela, é intuitivo marcar as linhas definidas para cada coluna. Garanta que seu ambiente está marcado com:
Key à CustomerKey
Input à Age e CommuteDistance
Predictable à BikeBuyer
Como apresentado a seguir
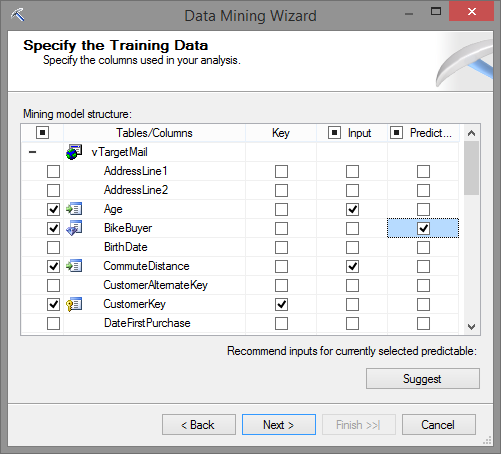
Avance para a próxima tela, e informe quais são valores Continuous ou então Discrete. Lembrando que valores contínuos apresentam uma grande variação de ocorrencias dentro da coluna e os discretos variam pouco. Por exemplo um campo do tipo CPF é um valor contínuo (varia muito de individuo para individuo) e uma coluna do tipo sexo é discreto (varia só um pouco). Caso não esteja a vontade, ou não conhece a base, pode clicar em Detect e o SQL Server analisa e lhe dá o resultado.
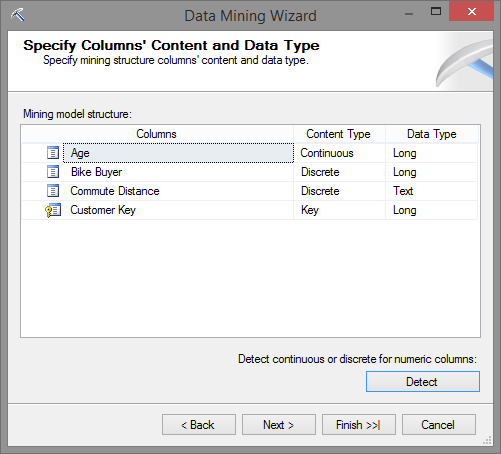
O próximo passo é finalizar e informar o nome. Como não estou com criatividade hoje, vou deixar o nome sugerido pelo SQL Server e vou manter v Target Mail.
Um novo item é criado dentro da Solution Explorer, e é neste objeto que a Mineração de Dados ocorre. Para encontrar a Árvore de Decisão, é preciso processar os dados. É possível processar somente o modelo ou então o projeto como um todo. No caso, vamos processar todo o projeto. Para isso, vá na Solution Explorer, clique com o botão direito no projeto e aponte para Process. Lembrando de apontar para o deploy para o servidor correto.
Se tudo ocorrer bem ao processamento, será apresenta o status Process Succeeded.
Para encontrar a Árvore de Decisão, vá até a área central do SQL Server Data Tools no objeto v Target Mail, e abra a aba Mining Model Viewer.
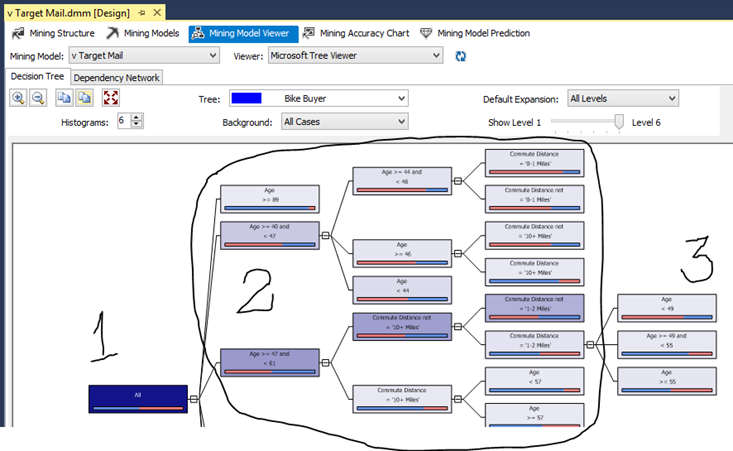
Reparem que os nós Raiz [1], Ramificações [2] e Folha [3] são apresentados, e pode-se seguir o caminho da predição com base nas variáveis de entrada. Um ponto importante para seguir com a análise, é entender essa graduação de cores, na qual o item mais escuro representa o resultado mais impactante com base na predição esperada. A base do AdventureWorks é de uma empresa fictícia de venda de acessórios para bicicletas, então, olhando esta árvore, é possível predizer que os melhores clientes para realizar possíveis compras futuras seguindo o fluxo com as cores mais escuras.
Agora é com vocês, apliquem estas técnicas de mineração de dados em seu ambiente e façam com que seus resultados sejam mais assertivos!
